
Arquitectura
El extractor está construido en torno a una fábrica abstracta por servicio. Todo lo demás, el manejo de URLs, la descarga, la paginación, la construcción del modelo, cuelga de esa fábrica con una forma fija. Aprende la forma una vez y todos los servicios se leen igual.
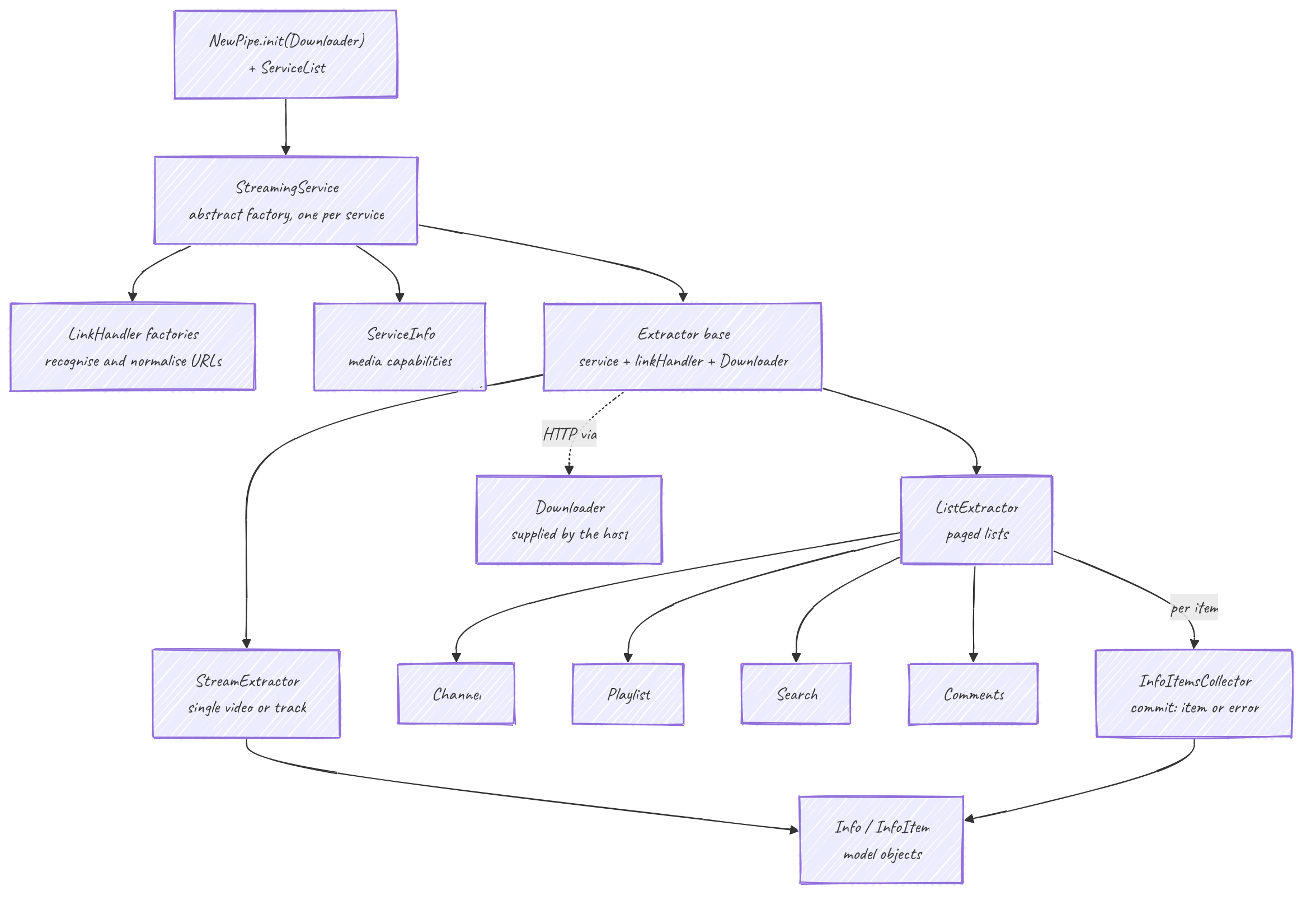
Arranque: NewPipe y ServiceList
Nada funciona hasta que se inicializa la biblioteca. NewPipe.init(Downloader d) se llama una vez al arrancar (hay sobrecargas que toman un Localization y un ContentCountry). Guarda el downloader y la localización por defecto de forma global.
ServiceList es el registro: un array fijo de instancias StreamingService, cada una creada con un serviceId constante. Ese id se asigna aquí y en ningún otro sitio, así que se mantiene estable entre ejecuciones y puede persistirse. Las búsquedas pasan por NewPipe:
NewPipe.getService(int serviceId)
NewPipe.getService(String serviceName)
NewPipe.getServiceByUrl(String url) // asks each service if it accepts the URL
NewPipe.getServices()Cada Extractor saca el downloader de NewPipe.getDownloader() en su constructor, así que init() tiene que ejecutarse antes de construir nada.
StreamingService: la fábrica por servicio
Un servicio es una abstract class StreamingService, construida con (int id, String name, List<MediaCapability>). El id viene de ServiceList, nunca de dentro de la implementación. Su ServiceInfo lleva las capacidades que el resto del código comprueba antes de ofrecer una función:
enum MediaCapability { AUDIO, VIDEO, LIVE, COMMENTS, BULLET_COMMENTS, SPONSORBLOCK }El servicio reparte dos familias de objetos.
Fábricas LinkHandler, una por tipo de contenido:
abstract LinkHandlerFactory getStreamLHFactory();
abstract ListLinkHandlerFactory getChannelLHFactory();
abstract ListLinkHandlerFactory getChannelTabLHFactory();
abstract ListLinkHandlerFactory getPlaylistLHFactory();
abstract SearchQueryHandlerFactory getSearchQHFactory();
abstract ListLinkHandlerFactory getCommentsLHFactory();Extractores, construidos a partir de un handler:
abstract StreamExtractor getStreamExtractor(LinkHandler handler);
abstract ChannelExtractor getChannelExtractor(ListLinkHandler handler);
abstract PlaylistExtractor getPlaylistExtractor(ListLinkHandler handler);
abstract SearchExtractor getSearchExtractor(SearchQueryHandler handler);
abstract CommentsExtractor getCommentsExtractor(ListLinkHandler handler);
abstract SuggestionExtractor getSuggestionExtractor();
abstract SubscriptionExtractor getSubscriptionExtractor();
abstract KioskList getKioskList();Hay sobrecargas de conveniencia que toman una cadena en bruto y la pasan por la fábrica correspondiente, de modo que quien llama rara vez construye handlers a mano:
public StreamExtractor getStreamExtractor(String url) throws ExtractionException {
return getStreamExtractor(getStreamLHFactory().fromUrl(url));
}Por último, getLinkTypeByUrl(String url) devuelve un LinkType (NONE, STREAM, CHANNEL, PLAYLIST) preguntando a cada fábrica LinkHandler si acepta la URL. Así es como la app encamina un enlace pegado cualquiera hacia el tipo de extractor correcto.
LinkHandler: URLs dentro, ids estables fuera
Un LinkHandler es una terna inmutable: la URL original, una URL canónica normalizada y el id extraído. ListLinkHandler añade filtros de contenido y un orden de clasificación; SearchQueryHandler lleva la cadena de la consulta.
La fábrica hace el reconocimiento:
abstract String getId(String url);
abstract String getUrl(String id);
abstract boolean onAcceptUrl(String url);
public LinkHandler fromUrl(String url) // acceptUrl() then build (canonical url + id)
public LinkHandler fromId(String id) // the other directionLa idea es que el reconocimiento y la normalización ocurren antes de cualquier llamada de red. Una URL desordenada de compartir o de móvil se convierte en una URL canónica más un id estable en los que el resto del pipeline puede confiar.
Extractor: la base del ciclo de vida
Todo extractor concreto extiende Extractor. La base guarda tres cosas: el service propietario, el linkHandler y el downloader (resuelto desde NewPipe.getDownloader() en la construcción).
La identidad es gratis, lo demás cuesta una descarga:
getId(), getUrl(), getOriginalUrl(), getBaseUrl() // delegate to linkHandler, no network
getName() // abstract, needs the pagefetchPage() es la puerta idempotente. Llama al abstracto onFetchPage(Downloader) exactamente una vez, protegido por un flag pageFetched, y los extractores concretos hacen toda su E/S en onFetchPage. Los getters que necesitan datos descargados llaman primero a assertPageFetched(), así que leer antes de una descarga lanza una IllegalStateException en lugar de devolver basura.
ListExtractor: paginación
Todo lo que devuelve una lista, channel, playlist, búsqueda, comentarios, extiende ListExtractor<R extends InfoItem>:
abstract InfoItemsPage<R> getInitialPage();
abstract InfoItemsPage<R> getPage(Page page); // a continuationInfoItemsPage agrupa los elementos, el token de la siguiente Page y cualquier error por elemento, con hasNextPage(). Los tamaños que no pueden conocerse de antemano usan centinelas: ITEM_COUNT_UNKNOWN, ITEM_COUNT_INFINITE, ITEM_COUNT_MORE_THAN_100.
StreamExtractor es la excepción: un flujo es un único elemento, así que extiende Extractor directamente, no ListExtractor.
Colectores: construcción de modelo tolerante a errores
Una página no construye los InfoItem a mano. Por cada entrada en bruto envuelve un fino InfoItemExtractor (que lee los campos de una tarjeta) y llama a:
collector.commit(extractor); // runs extract(); addItem() on success, addError() on ParsingExceptionAsí, una tarjeta rota acaba en getErrors() en lugar de hundir toda la página; getItems() devuelve todo lo que se parseó. Esto es deliberado: los servicios cambian su marcado constantemente, y una sola entrada inesperada debería degradar una fila, no el feed.
La salida de todo esto es el modelo Info / InfoItem que consume la app.
Ese es el mapa estático. Para ver estas piezas en funcionamiento en una petición real, desde una URL pegada hasta un StreamInfo terminado, continúa en Flujo de extracción.