
El extractor
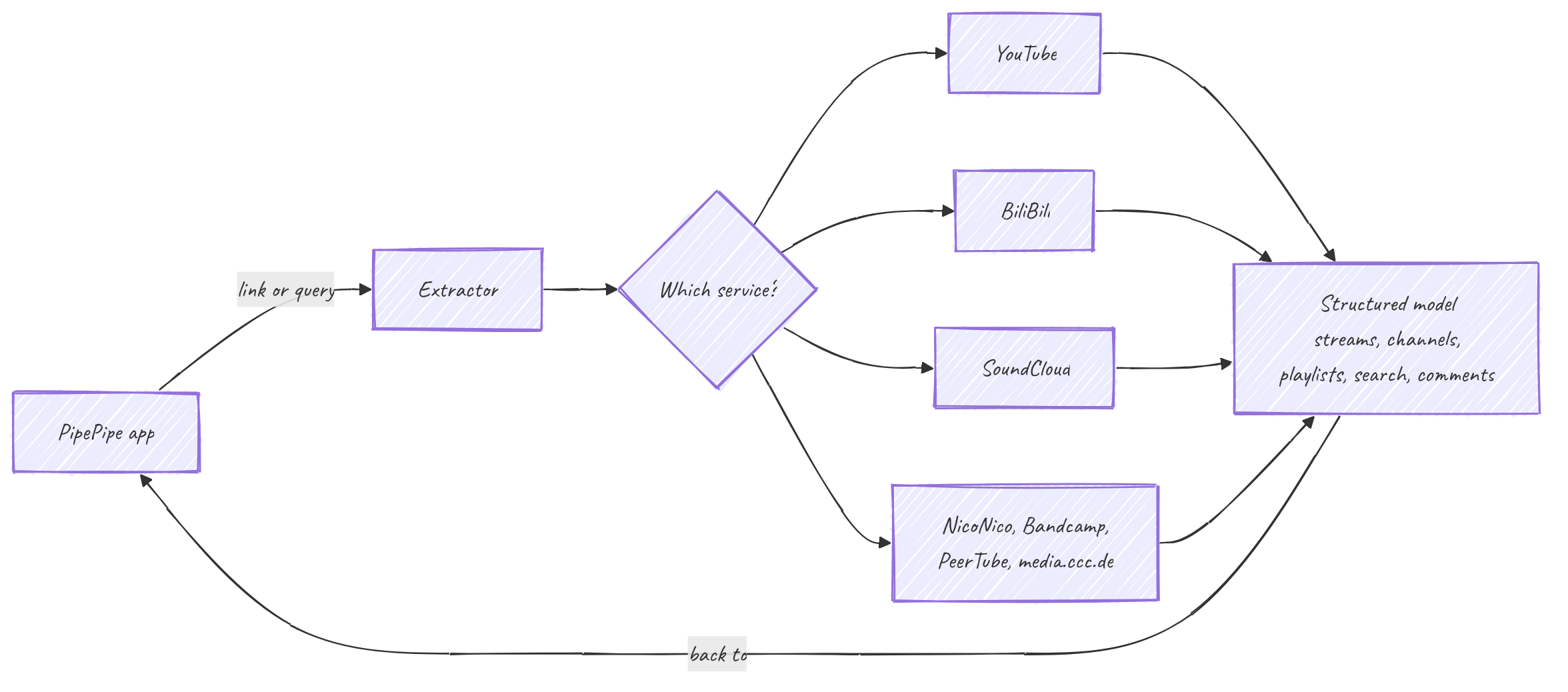
PipePipe nunca habla directamente con YouTube, BiliBili o SoundCloud. El acceso a los servicios vive en el extractor, una biblioteca Java autónoma de la que depende la app. Le das un enlace o una consulta de búsqueda y te devuelve objetos de modelo estructurados: un vídeo con sus flujos, un channel con sus pestañas, una playlist, una página de resultados, un hilo de comentarios. En la app no ocurre ningún parseo de HTML ni ninguna llamada a las API de los servicios.
Empezó como un fork del extractor de NewPipe, y la ruta del paquete (org.schabi.newpipe.extractor) todavía lo delata. Vale la pena decirlo una vez y luego dejarlo de lado: las dos bases de código han divergido mucho. Los servicios, las abstracciones, el parseo y el comportamiento difieren lo suficiente como para que la documentación, los issues y los parches de NewPipe rara vez encajen limpiamente en PipePipe. Trátalo como su propia base de código, no como un espejo de NewPipe.
El módulo es autocontenido. Se compila y se prueba por sí solo, sin la app Android alrededor, contra una pequeña abstracción Downloader que el host proporciona.
Servicios cubiertos hoy: YouTube, BiliBili, NicoNico, SoundCloud, Bandcamp, PeerTube y media.ccc.de. Cada uno es una implementación separada de un mismo conjunto compartido de interfaces. Ese es el diseño: el resto del código está escrito contra las abstracciones, nunca contra un sitio concreto. "Obtener los flujos de este vídeo" es la misma llamada tanto si el backend es YouTube como SoundCloud; el desorden propio de cada servicio se queda detrás de la interfaz.
Esa uniformidad es también la razón por la que el extractor es la capa frágil. Las interfaces son estables; los sitios que hay detrás no lo son. Un servicio puede cambiar su maquetación o su API de la noche a la mañana y romper la extracción de ese único servicio mientras los demás siguen funcionando. La mayor parte del trabajo aquí consiste en mantener cada servicio al día con un sitio que nunca aceptó ser parseado, y YouTube es el ejemplo más ruidoso.
Qué cubre esta sección
Un recorrido a nivel de desarrollador sobre cómo está construido el extractor, para quienes contribuyen leyendo el código.
- Arquitectura: el punto de entrada
StreamingServicey la familia de extractores que cuelga de él. - Flujo de extracción: qué ocurre desde una URL hasta un
StreamInfoterminado. - Flujos y delivery: cómo se describe el medio una vez terminada la extracción, los flujos, los formatos y los
DeliveryMethodque consume el reproductor. Aquí es también donde conecta con SABR.