
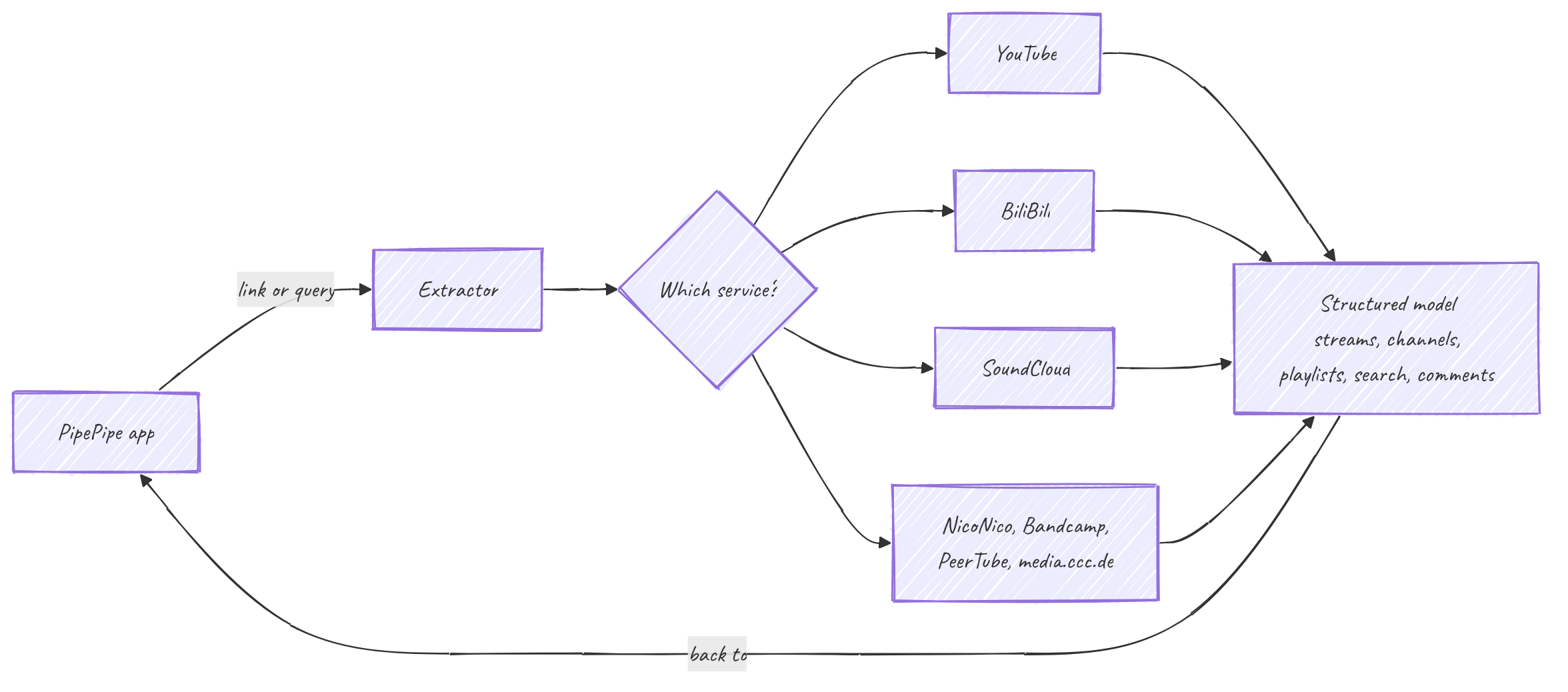
L'extracteur
PipePipe ne dialogue jamais directement avec YouTube, BiliBili ou SoundCloud. L'accès aux services vit dans l'extracteur, une bibliothèque Java autonome dont l'application dépend. Vous lui donnez un lien ou une requête de recherche ; il renvoie des objets de modèle structurés : une vidéo avec ses flux, un channel avec ses onglets, une playlist, une page de résultats, un fil de commentaires. Aucun parsing de HTML ni appel d'API de service n'a lieu dans l'application.
Il a commencé comme un fork de l'extracteur de NewPipe, et le chemin de package (org.schabi.newpipe.extractor) en porte encore la trace. Cela mérite d'être dit une fois, puis mis de côté : les deux bases de code ont fortement divergé. Les services, les abstractions, le parsing et le comportement diffèrent suffisamment pour que la documentation, les issues et les patchs de NewPipe se transposent rarement proprement sur PipePipe. Considérez-la comme une base de code à part entière, pas comme un miroir de NewPipe.
Le module est autonome. Il se compile et se teste seul, sans l'application Android autour de lui, face à une petite abstraction Downloader fournie par l'hôte.
Services couverts aujourd'hui : YouTube, BiliBili, NicoNico, SoundCloud, Bandcamp, PeerTube et media.ccc.de. Chacun est une implémentation distincte d'un même ensemble d'interfaces partagées. C'est le principe de conception : le reste du code est écrit face aux abstractions, jamais face à un site précis. « Récupérer les flux de cette vidéo » est le même appel que le backend soit YouTube ou SoundCloud ; le désordre propre à chaque service reste derrière l'interface.
Cette uniformité est aussi la raison pour laquelle l'extracteur est la couche fragile. Les interfaces sont stables ; les sites derrière elles ne le sont pas. Un service peut changer sa mise en page ou son API du jour au lendemain et casser l'extraction pour lui seul pendant que les autres continuent de fonctionner. L'essentiel du travail ici consiste à maintenir chaque service au pas avec un site qui n'a jamais accepté d'être parsé, et YouTube en est l'exemple le plus bruyant.
Ce que couvre cette section
Une visite de niveau développeur de la façon dont l'extracteur est construit, destinée aux contributeurs qui lisent le code.
- Architecture : le point d'entrée
StreamingServiceet la famille d'extracteurs qui en découle. - Flux d'extraction : ce qui se passe d'une URL jusqu'à un
StreamInfoterminé. - Flux et delivery : comment le média est décrit une fois l'extraction terminée, les flux, formats et
DeliveryMethodque le player consomme. C'est aussi là que cela rejoint SABR.