
Architecture
L'extracteur est bâti autour d'une fabrique abstraite par service. Tout le reste, la gestion des URLs, le fetch, la pagination, la construction du modèle, découle de cette fabrique selon une forme fixe. Apprenez la forme une fois et chaque service se lit de la même manière.
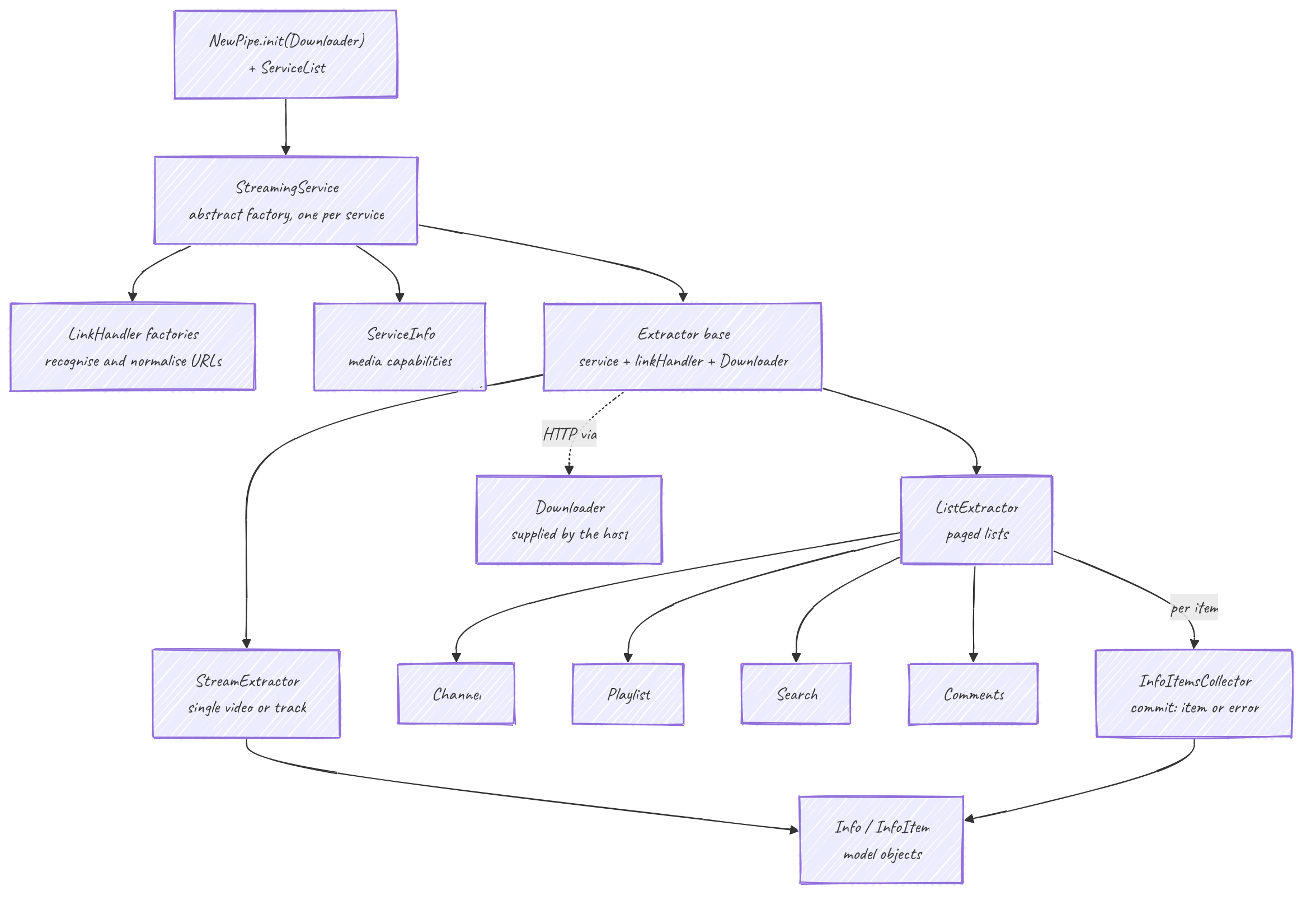
Bootstrap : NewPipe et ServiceList
Rien ne fonctionne tant que la bibliothèque n'est pas initialisée. NewPipe.init(Downloader d) est appelé une fois au démarrage (des surcharges prennent une Localization et une ContentCountry). Cela stocke globalement le downloader et la localisation par défaut.
ServiceList est le registre : un tableau fixe d'instances StreamingService, chacune créée avec un serviceId constant. Cet id est attribué ici et nulle part ailleurs, donc il reste stable d'une exécution à l'autre et peut être persisté. Les recherches passent par NewPipe :
NewPipe.getService(int serviceId)
NewPipe.getService(String serviceName)
NewPipe.getServiceByUrl(String url) // asks each service if it accepts the URL
NewPipe.getServices()Chaque Extractor récupère le downloader depuis NewPipe.getDownloader() dans son constructeur, donc init() doit s'exécuter avant de construire quoi que ce soit.
StreamingService : la fabrique par service
Un service est une abstract class StreamingService, construite avec (int id, String name, List<MediaCapability>). L'id vient de ServiceList, jamais de l'intérieur de l'implémentation. Son ServiceInfo porte les capacités que le reste du code vérifie avant de proposer une fonctionnalité :
enum MediaCapability { AUDIO, VIDEO, LIVE, COMMENTS, BULLET_COMMENTS, SPONSORBLOCK }Le service distribue deux familles d'objets.
Les fabriques de LinkHandler, une par type de contenu :
abstract LinkHandlerFactory getStreamLHFactory();
abstract ListLinkHandlerFactory getChannelLHFactory();
abstract ListLinkHandlerFactory getChannelTabLHFactory();
abstract ListLinkHandlerFactory getPlaylistLHFactory();
abstract SearchQueryHandlerFactory getSearchQHFactory();
abstract ListLinkHandlerFactory getCommentsLHFactory();Les extracteurs, construits à partir d'un handler :
abstract StreamExtractor getStreamExtractor(LinkHandler handler);
abstract ChannelExtractor getChannelExtractor(ListLinkHandler handler);
abstract PlaylistExtractor getPlaylistExtractor(ListLinkHandler handler);
abstract SearchExtractor getSearchExtractor(SearchQueryHandler handler);
abstract CommentsExtractor getCommentsExtractor(ListLinkHandler handler);
abstract SuggestionExtractor getSuggestionExtractor();
abstract SubscriptionExtractor getSubscriptionExtractor();
abstract KioskList getKioskList();Il existe des surcharges de confort qui prennent une chaîne brute et la passent par la fabrique correspondante, si bien que les appelants construisent rarement les handlers à la main :
public StreamExtractor getStreamExtractor(String url) throws ExtractionException {
return getStreamExtractor(getStreamLHFactory().fromUrl(url));
}Enfin, getLinkTypeByUrl(String url) renvoie un LinkType (NONE, STREAM, CHANNEL, PLAYLIST) en demandant à chaque fabrique de LinkHandler si elle accepte l'URL. C'est ainsi que l'application achemine un lien collé quelconque vers le bon type d'extracteur.
LinkHandler : des URLs en entrée, des ids stables en sortie
Un LinkHandler est un triplet immuable : l'URL d'origine, une URL canonique normalisée, et l'id extrait. ListLinkHandler ajoute des filtres de contenu et un ordre de tri ; SearchQueryHandler porte la chaîne de requête.
La fabrique se charge de la reconnaissance :
abstract String getId(String url);
abstract String getUrl(String id);
abstract boolean onAcceptUrl(String url);
public LinkHandler fromUrl(String url) // acceptUrl() then build (canonical url + id)
public LinkHandler fromId(String id) // the other directionL'intérêt, c'est que la reconnaissance et la normalisation ont lieu avant tout appel réseau. Une URL de partage ou mobile mal formée devient une URL canonique plus un id stable auquel le reste du pipeline peut se fier.
Extractor : la base du cycle de vie
Tout extracteur concret étend Extractor. La base détient trois choses : le service propriétaire, le linkHandler, et le downloader (résolu depuis NewPipe.getDownloader() à la construction).
L'identité est gratuite, le reste coûte un fetch :
getId(), getUrl(), getOriginalUrl(), getBaseUrl() // delegate to linkHandler, no network
getName() // abstract, needs the pagefetchPage() est le verrou idempotent. Il appelle l'abstrait onFetchPage(Downloader) exactement une fois, protégé par un flag pageFetched, et les extracteurs concrets font toutes leurs entrées/sorties dans onFetchPage. Les getters qui ont besoin de données fetchées appellent assertPageFetched() d'abord, si bien que lire avant un fetch lève une IllegalStateException au lieu de renvoyer n'importe quoi.
ListExtractor : la pagination
Tout ce qui renvoie une liste, channel, playlist, recherche, commentaires, étend ListExtractor<R extends InfoItem> :
abstract InfoItemsPage<R> getInitialPage();
abstract InfoItemsPage<R> getPage(Page page); // a continuationInfoItemsPage regroupe les items, le jeton de Page suivante et les éventuelles erreurs par item, avec hasNextPage(). Les tailles qui ne peuvent pas être connues d'avance utilisent des sentinelles : ITEM_COUNT_UNKNOWN, ITEM_COUNT_INFINITE, ITEM_COUNT_MORE_THAN_100.
StreamExtractor est l'exception : un flux est un item unique, donc il étend Extractor directement, pas ListExtractor.
Les collectors : construction de modèle tolérante aux erreurs
Une page ne construit pas les InfoItem à la main. Pour chaque entrée brute, elle enveloppe un mince InfoItemExtractor (qui lit les champs d'une carte) et appelle :
collector.commit(extractor); // runs extract(); addItem() on success, addError() on ParsingExceptionAinsi, une carte cassée atterrit dans getErrors() au lieu de couler toute la page ; getItems() renvoie tout ce qui a été parsé. C'est délibéré : les services changent constamment leur balisage, et une seule entrée inattendue ne devrait dégrader qu'une ligne, pas le flux.
La sortie de tout cela est le modèle Info / InfoItem que l'application consomme.
Voilà la carte statique. Pour voir ces pièces tourner sur une vraie requête, d'une URL collée jusqu'à un StreamInfo terminé, continuez vers Flux d'extraction.