
Le modèle InfoItem
L'extraction produit deux formes de données : un Info complet pour la chose unique que vous avez ouverte, et une liste de cartes InfoItem pour tout le reste. Les deux sont construites de la même manière tolérante aux erreurs.
Info : l'objet lourd
Info est la base des objets détaillés (StreamInfo, ChannelInfo, PlaylistInfo, CommentsInfo). Il porte l'identité et une liste d'erreurs tolérées :
int getServiceId(); String getId(); String getUrl(); String getOriginalUrl(); String getName();
List<Throwable> getErrors(); void addError(Throwable t);Cette liste d'erreurs est toute la raison pour laquelle une page à moitié cassée renvoie quand même quelque chose : chaque étape d'extraction optionnelle y ajoute au lieu de lever une exception.
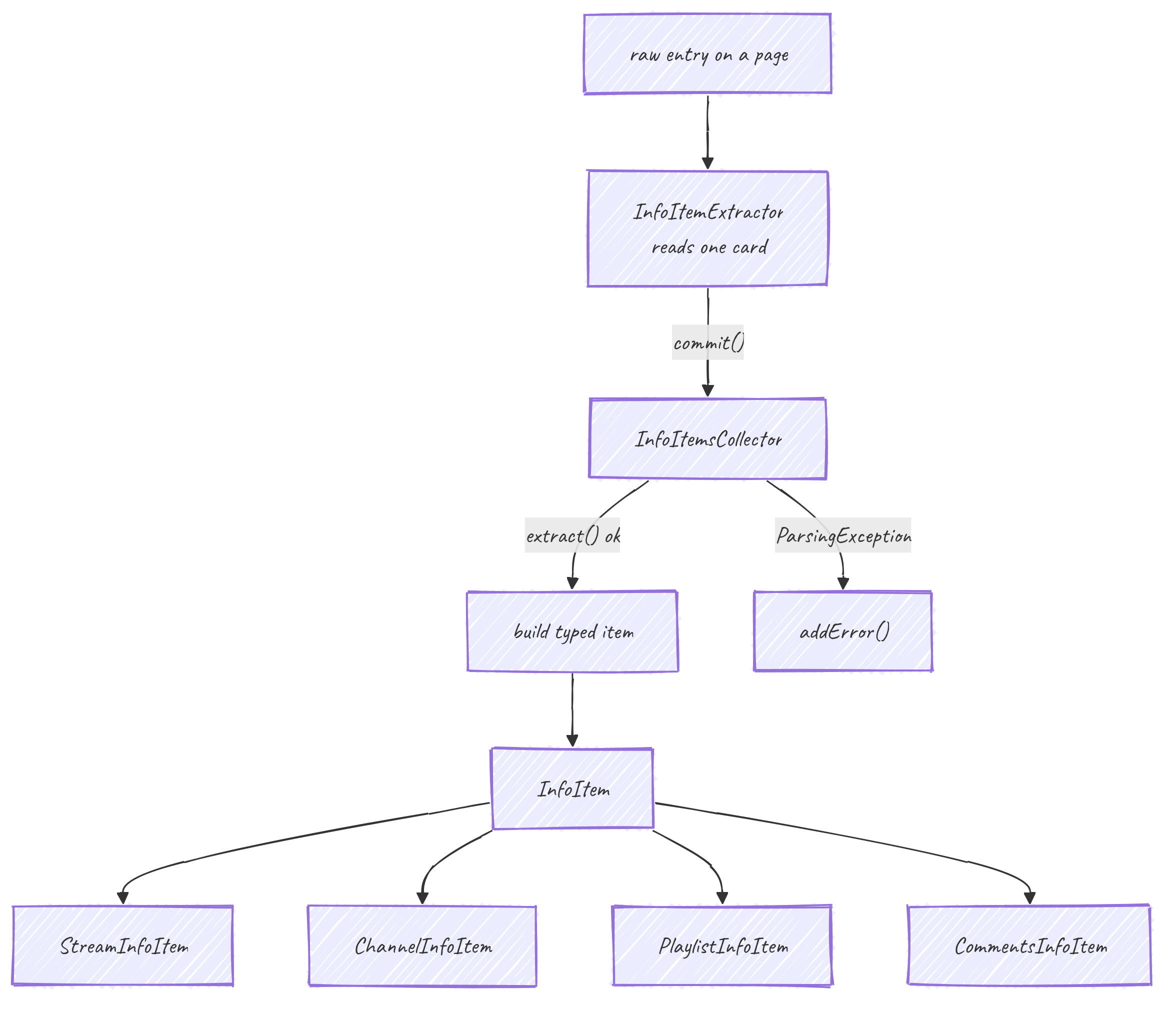
InfoItem : la carte légère
InfoItem est la base des entrées de liste, délibérément mince, juste assez pour afficher une ligne :
enum InfoType { STREAM, PLAYLIST, CHANNEL, STAFF, COMMENT, BULLET_COMMENT }
InfoType getInfoType(); int getServiceId(); String getUrl(); String getName(); String getThumbnailUrl();Les sous-classes concrètes ajoutent leurs propres champs :
StreamInfoItem:streamType,duration,uploaderName,viewCount,textualUploadDate+DateWrapper,uploaderVerified,shortFormContent, ...ChannelInfoItem:description,subscriberCount,streamCount,verified.PlaylistInfoItem:uploaderName,streamCount,playlistType.CommentsInfoItem:commentText,likeCount,pinned,replyCount, et unePagede réponses (voir Commentaires).
InfoItemExtractor : une carte, paresseusement
Vous ne construisez jamais un InfoItem à partir de JSON brut à la main. Vous écrivez un InfoItemExtractor, un petit objet qui lit les champs d'une carte à la demande :
interface InfoItemExtractor { String getName(); String getUrl(); String getThumbnailUrl(); }avec des sous-interfaces typées (StreamInfoItemExtractor, ChannelInfoItemExtractor, ...) qui ajoutent getDuration, getViewCount, et ainsi de suite. La plupart de ces méthodes sont default et renvoient une valeur vide sûre, si bien qu'un service ne surcharge que ce dont il dispose réellement.
Les collectors : extracteur en entrée, item en sortie
Un collector transforme les extracteurs en items, avec tolérance :
collector.commit(extractor); // extract(): addItem() on success, addError() on ParsingException / FoundAdException
List<I> getItems(); List<Throwable> getErrors();Il y en a un par type (StreamInfoItemsCollector, ChannelInfoItemsCollector, PlaylistInfoItemsCollector, CommentsInfoItemsCollector). extract() est là où l'item typé est assemblé champ par champ, chaque champ optionnel étant enveloppé pour qu'une valeur manquante ne fasse pas perdre toute la ligne.
MultiInfoItemsCollector gère les listes mixtes (une recherche renvoie des flux, des channels et des playlists ensemble) : il détient un collector par type et achemine chaque extracteur vers le bon selon son interface. Un collector peut aussi porter un Comparator pour garder les items triés, et prend en charge le blocage de contenu (applyBlocking) pour écarter des items par mot-clé, channel, shorts ou indicateur payant.
Les images
Les miniatures et avatars passent de simples chaînes d'URL à un Image plus riche :
class Image { String getUrl(); int getHeight(); int getWidth(); ResolutionLevel getEstimatedResolutionLevel(); }
enum ResolutionLevel { HIGH, MEDIUM, LOW, UNKNOWN } // bucketed by pixel heightImageSuffix est la variante template (un suffixe de chemin plus une taille cible) pour les services qui exposent une image de base à plusieurs résolutions. InfoItem conserve toujours un getThumbnailUrl() pour le cas simple.
StreamType
Chaque flux et chaque item de flux est étiqueté d'un StreamType :
VIDEO_STREAM, AUDIO_STREAM, LIVE_STREAM, AUDIO_LIVE_STREAM,
POST_LIVE_STREAM, POST_LIVE_AUDIO_STREAM, NONELe player branche dessus (live vs VOD, audio seul vs vidéo), et l'application aussi quand elle décide quels contrôles afficher.