
The InfoItem model
Extraction produces two shapes of data: a full Info for the single thing you opened, and a list of InfoItem cards for everything else. Both are built the same error-tolerant way.
Info: the heavy object
Info is the base for the detailed objects (StreamInfo, ChannelInfo, PlaylistInfo, CommentsInfo). It carries identity and a tolerated-error list:
int getServiceId(); String getId(); String getUrl(); String getOriginalUrl(); String getName();
List<Throwable> getErrors(); void addError(Throwable t);That error list is the whole reason a half-broken page still returns something: each optional extraction step appends to it instead of throwing.
InfoItem: the lightweight card
InfoItem is the base for list entries, deliberately thin, just enough to render a row:
enum InfoType { STREAM, PLAYLIST, CHANNEL, STAFF, COMMENT, BULLET_COMMENT }
InfoType getInfoType(); int getServiceId(); String getUrl(); String getName(); String getThumbnailUrl();Concrete subclasses add their own fields:
StreamInfoItem:streamType,duration,uploaderName,viewCount,textualUploadDate+DateWrapper,uploaderVerified,shortFormContent, ...ChannelInfoItem:description,subscriberCount,streamCount,verified.PlaylistInfoItem:uploaderName,streamCount,playlistType.CommentsInfoItem:commentText,likeCount,pinned,replyCount, and a repliesPage(see Comments).
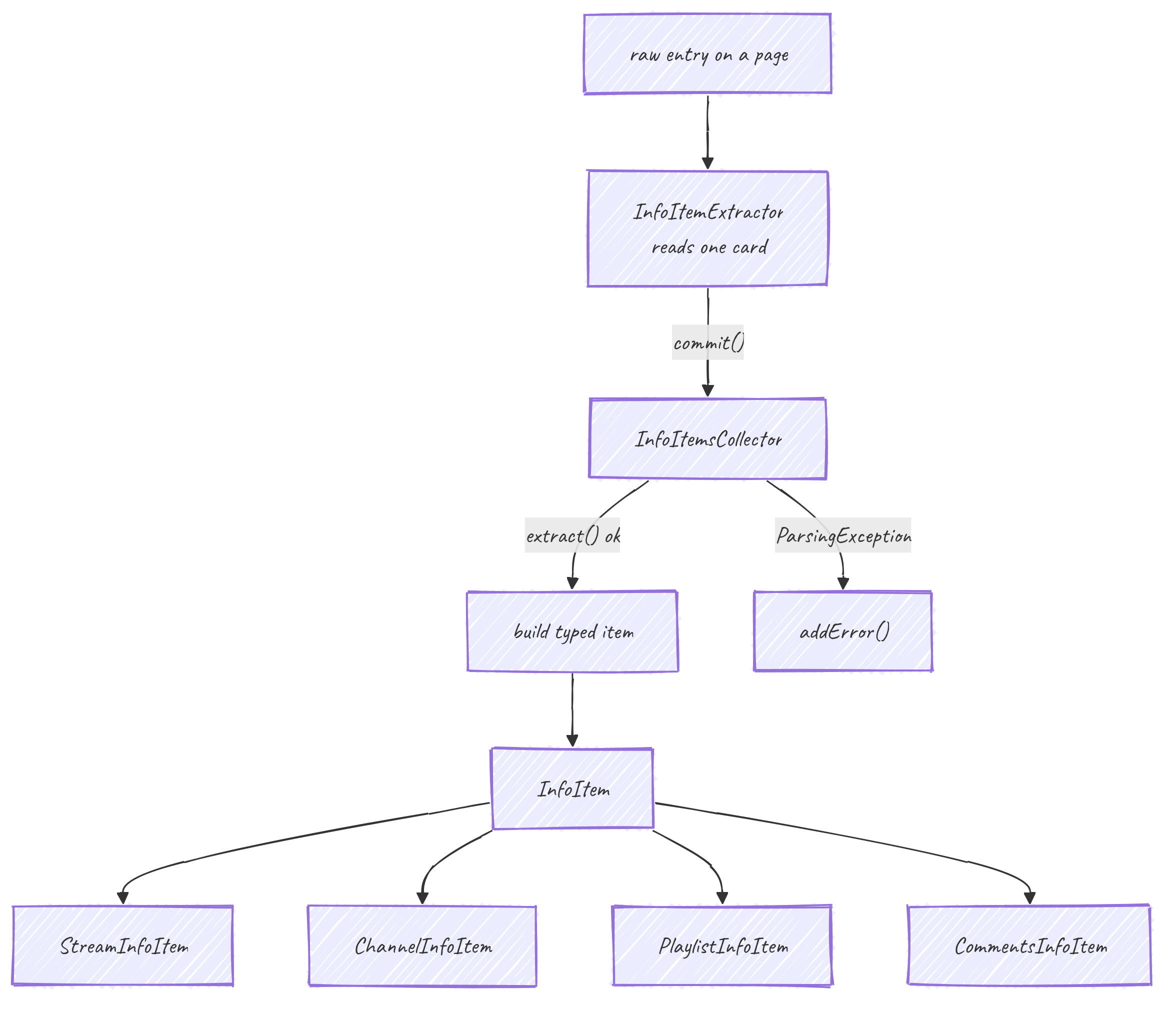
InfoItemExtractor: one card, lazily
You never build an InfoItem from raw JSON by hand. You write an InfoItemExtractor, a tiny object that reads one card's fields on demand:
interface InfoItemExtractor { String getName(); String getUrl(); String getThumbnailUrl(); }with typed sub-interfaces (StreamInfoItemExtractor, ChannelInfoItemExtractor, ...) adding getDuration, getViewCount, and so on. Most of those methods are default and return a safe empty value, so a service overrides only what it actually has.
Collectors: extractor in, item out
A collector turns extractors into items, tolerantly:
collector.commit(extractor); // extract(): addItem() on success, addError() on ParsingException / FoundAdException
List<I> getItems(); List<Throwable> getErrors();There is one per type (StreamInfoItemsCollector, ChannelInfoItemsCollector, PlaylistInfoItemsCollector, CommentsInfoItemsCollector). extract() is where the typed item is assembled field by field, each optional field wrapped so one missing value does not lose the whole row.
MultiInfoItemsCollector handles mixed lists (a search returns streams, channels, and playlists together): it holds one collector per type and routes each extractor to the right one by its interface. A collector can also carry a Comparator to keep items sorted, and supports content blocking (applyBlocking) to drop items by keyword, channel, shorts, or paid flag.
Images
Thumbnails and avatars are moving from bare URL strings to a richer Image:
class Image { String getUrl(); int getHeight(); int getWidth(); ResolutionLevel getEstimatedResolutionLevel(); }
enum ResolutionLevel { HIGH, MEDIUM, LOW, UNKNOWN } // bucketed by pixel heightImageSuffix is the template variant (a path suffix plus a target size) for services that expose one base image at several resolutions. InfoItem still keeps a getThumbnailUrl() for the simple path.
StreamType
Every stream and stream item is tagged with a StreamType:
VIDEO_STREAM, AUDIO_STREAM, LIVE_STREAM, AUDIO_LIVE_STREAM,
POST_LIVE_STREAM, POST_LIVE_AUDIO_STREAM, NONEThe player branches on it (live vs VOD, audio-only vs video), and so does the app when it decides which controls to show.