
Extraction flow
Here is one request end to end: a YouTube watch URL turned into a StreamInfo. The skeleton is the same for every service and every content type. Only onFetchPage and the getters change.
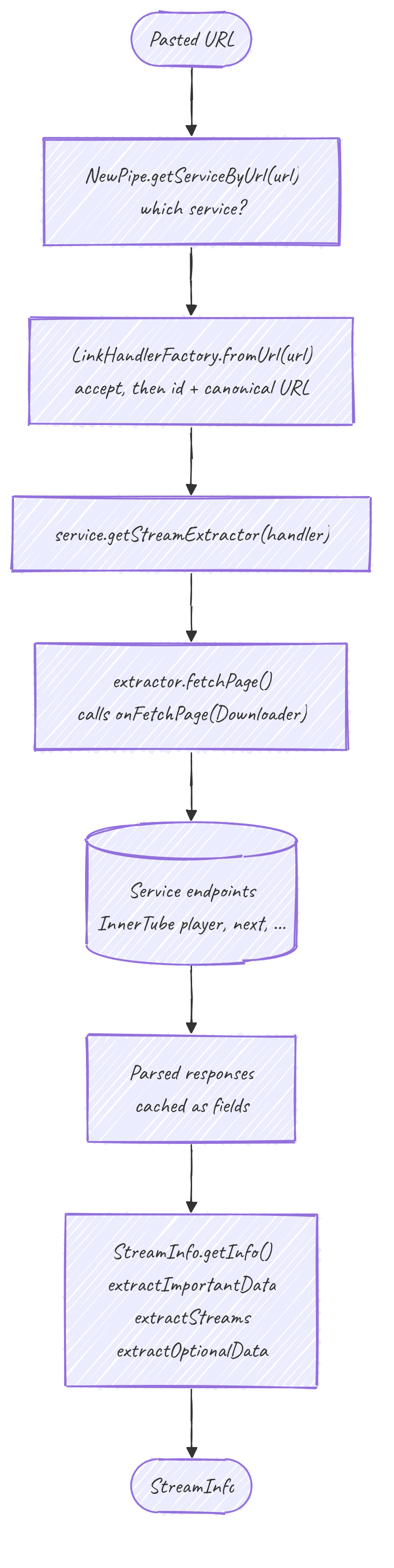
From URL to extractor
StreamInfo.getInfo(String url) is the public entry point. It resolves the service, then builds the extractor:
getInfo(url)
-> getInfo(NewPipe.getServiceByUrl(url), url)
-> getInfo(service.getStreamExtractor(url));getStreamExtractor(url) runs the URL through getStreamLHFactory().fromUrl(url). The factory accepts the URL, extracts the id, and produces a canonical URL. No network yet: the result is just a validated LinkHandler, and the extractor it feeds knows its id and URL before it has fetched anything.
The fetch
getInfo(extractor) calls extractor.fetchPage() once, which delegates to the concrete onFetchPage(Downloader). This is where the I/O lives.
Take YoutubeStreamExtractor.onFetchPage as the concrete case. It reads the videoId from getId() and fires several InnerTube requests in parallel through the downloader's async API (CancellableCall):
- a web player response,
- an android-VR or safari player response, chosen depending on whether tokens are set,
- the next endpoint for metadata,
- best-effort side calls (return-dislike, and SponsorBlock on its own thread).
public void onFetchPage(@Nonnull final Downloader downloader) {
final String videoId = getId();
...
CancellableCall webPageCall = YoutubeParsingHelper.getWebPlayerResponse(...);
if (StringUtils.isBlank(ServiceList.YouTube.getTokens())) {
androidCall = fetchAndroidVRJsonPlayer(...);
} else {
safariCall = fetchSafariJsonPlayer(...);
}
CancellableCall nextDataCall = getJsonPostResponseAsync(NEXT, body, ...);
...
}The parsed JSON lands in fields on the extractor (nextResponse, the player responses, and so on). Nothing is returned: fetchPage() only primes the object. That is exactly why the getters call assertPageFetched() before touching anything.
Why several clients at once: different InnerTube clients expose different stream sets and trip different restrictions. The extractor pulls what it needs from each and merges them.
Building the model
Once the page is fetched, getInfo runs three passes. Each is wrapped so that a failure in one becomes a collected error on the StreamInfo rather than a total loss:
streamInfo = extractImportantData(extractor); // id, url, name, type, duration, age limit
extractStreams(streamInfo, extractor); // audio / video / video-only / subtitles
extractOptionalData(streamInfo, extractor); // description, thumbnails, uploader, relatedextractImportantDatabuilds theStreamInfoand is the one pass that must succeed. The YouTube path here also disambiguates age-restricted from country-blocked and throwsContentNotAvailableExceptionwith the real server message instead of a misleading one.extractStreamspulls the playable formats. This is what the player ultimately consumes, and where theDeliveryMethod(progressive, DASH, HLS, SABR) is decided. That is the subject of Streams and delivery.extractOptionalDatais best-effort. A missing description or thumbnail degrades one field, it does not fail the video.
The same skeleton everywhere
Lists follow the identical shape with one extra step. Instead of a single getInfo, a ListExtractor returns getInitialPage(), and you walk getPage(nextPage) while hasNextPage() is true. The fetch, the cached fields, and the error-tolerant collection are all the same. Swap StreamExtractor for ChannelExtractor or SearchExtractor and the only things that really change are onFetchPage and how the fields are parsed.