
Flujo de extracción
Aquí tienes una petición de principio a fin: una URL de visualización de YouTube convertida en un StreamInfo. El esqueleto es el mismo para cada servicio y cada tipo de contenido. Solo cambian onFetchPage y los getters.
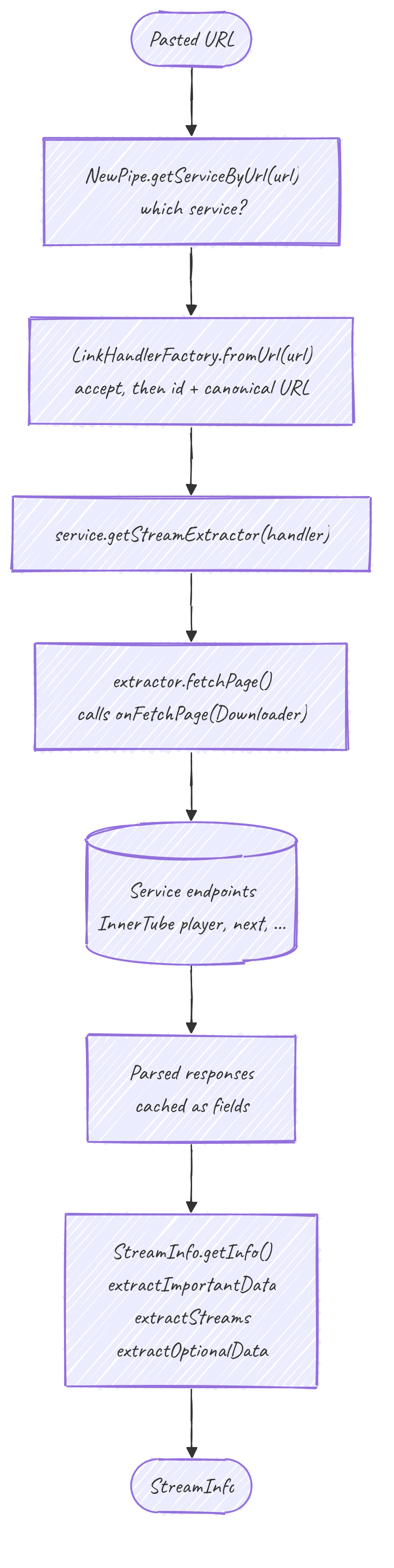
De la URL al extractor
StreamInfo.getInfo(String url) es el punto de entrada público. Resuelve el servicio y luego construye el extractor:
getInfo(url)
-> getInfo(NewPipe.getServiceByUrl(url), url)
-> getInfo(service.getStreamExtractor(url));getStreamExtractor(url) pasa la URL por getStreamLHFactory().fromUrl(url). La fábrica acepta la URL, extrae el id y produce una URL canónica. Todavía no hay red: el resultado es solo un LinkHandler validado, y el extractor que alimenta conoce su id y su URL antes de haber descargado nada.
La descarga
getInfo(extractor) llama a extractor.fetchPage() una vez, que delega en el onFetchPage(Downloader) concreto. Aquí es donde vive la E/S.
Toma YoutubeStreamExtractor.onFetchPage como caso concreto. Lee el videoId de getId() y dispara varias peticiones InnerTube en paralelo a través de la API asíncrona del downloader (CancellableCall):
- una respuesta del player web,
- una respuesta del player android-VR o safari, elegida según si hay tokens configurados,
- el endpoint next para los metadatos,
- llamadas laterales en el mejor de los casos (return-dislike, y SponsorBlock en su propio hilo).
public void onFetchPage(@Nonnull final Downloader downloader) {
final String videoId = getId();
...
CancellableCall webPageCall = YoutubeParsingHelper.getWebPlayerResponse(...);
if (StringUtils.isBlank(ServiceList.YouTube.getTokens())) {
androidCall = fetchAndroidVRJsonPlayer(...);
} else {
safariCall = fetchSafariJsonPlayer(...);
}
CancellableCall nextDataCall = getJsonPostResponseAsync(NEXT, body, ...);
...
}El JSON parseado aterriza en campos del extractor (nextResponse, las respuestas del player, etc.). No se devuelve nada: fetchPage() solo prepara el objeto. Por eso exactamente los getters llaman a assertPageFetched() antes de tocar nada.
Por qué varios clientes a la vez: distintos clientes InnerTube exponen distintos conjuntos de flujos y disparan distintas restricciones. El extractor saca lo que necesita de cada uno y los fusiona.
Construir el modelo
Una vez descargada la página, getInfo ejecuta tres pasadas. Cada una se envuelve de modo que un fallo en una se convierta en un error recogido en el StreamInfo en lugar de en una pérdida total:
streamInfo = extractImportantData(extractor); // id, url, name, type, duration, age limit
extractStreams(streamInfo, extractor); // audio / video / video-only / subtitles
extractOptionalData(streamInfo, extractor); // description, thumbnails, uploader, relatedextractImportantDataconstruye elStreamInfoy es la única pasada que debe tener éxito. El camino de YouTube aquí también distingue entre contenido restringido por edad y bloqueado por país, y lanzaContentNotAvailableExceptioncon el mensaje real del servidor en lugar de uno engañoso.extractStreamssaca los formatos reproducibles. Esto es lo que el reproductor consume al final, y donde se decide elDeliveryMethod(progressive, DASH, HLS, SABR). Ese es el tema de Flujos y delivery.extractOptionalDataes en el mejor de los casos. Una descripción o una miniatura que falte degrada un campo, no hace fallar el vídeo.
El mismo esqueleto en todas partes
Las listas siguen la forma idéntica con un paso extra. En lugar de un único getInfo, un ListExtractor devuelve getInitialPage(), y recorres getPage(nextPage) mientras hasNextPage() sea verdadero. La descarga, los campos cacheados y la recolección tolerante a errores son todos iguales. Cambia StreamExtractor por ChannelExtractor o SearchExtractor y lo único que cambia de verdad son onFetchPage y cómo se parsean los campos.