
Flux d'extraction
Voici une requête de bout en bout : une URL de visionnage YouTube transformée en StreamInfo. Le squelette est le même pour chaque service et chaque type de contenu. Seuls onFetchPage et les getters changent.
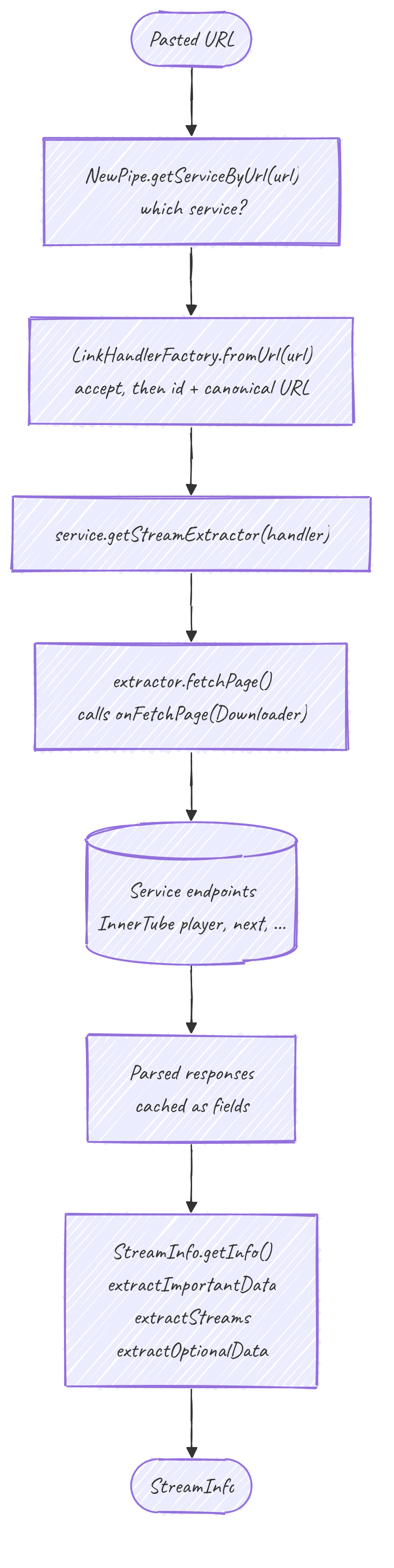
De l'URL à l'extracteur
StreamInfo.getInfo(String url) est le point d'entrée public. Il résout le service, puis construit l'extracteur :
getInfo(url)
-> getInfo(NewPipe.getServiceByUrl(url), url)
-> getInfo(service.getStreamExtractor(url));getStreamExtractor(url) passe l'URL par getStreamLHFactory().fromUrl(url). La fabrique accepte l'URL, extrait l'id et produit une URL canonique. Pas encore de réseau : le résultat n'est qu'un LinkHandler validé, et l'extracteur qu'il alimente connaît son id et son URL avant d'avoir fetché quoi que ce soit.
Le fetch
getInfo(extractor) appelle extractor.fetchPage() une fois, ce qui délègue au onFetchPage(Downloader) concret. C'est là que vivent les entrées/sorties.
Prenons YoutubeStreamExtractor.onFetchPage comme cas concret. Il lit le videoId depuis getId() et déclenche plusieurs requêtes InnerTube en parallèle via l'API asynchrone du downloader (CancellableCall) :
- une réponse player web,
- une réponse player android-VR ou safari, choisie selon que des tokens sont définis ou non,
- l'endpoint next pour les métadonnées,
- des appels annexes en best-effort (return-dislike, et SponsorBlock sur son propre thread).
public void onFetchPage(@Nonnull final Downloader downloader) {
final String videoId = getId();
...
CancellableCall webPageCall = YoutubeParsingHelper.getWebPlayerResponse(...);
if (StringUtils.isBlank(ServiceList.YouTube.getTokens())) {
androidCall = fetchAndroidVRJsonPlayer(...);
} else {
safariCall = fetchSafariJsonPlayer(...);
}
CancellableCall nextDataCall = getJsonPostResponseAsync(NEXT, body, ...);
...
}Le JSON parsé atterrit dans des champs de l'extracteur (nextResponse, les réponses player, etc.). Rien n'est renvoyé : fetchPage() ne fait qu'amorcer l'objet. C'est exactement pour cela que les getters appellent assertPageFetched() avant de toucher à quoi que ce soit.
Pourquoi plusieurs clients à la fois : différents clients InnerTube exposent des ensembles de flux différents et déclenchent des restrictions différentes. L'extracteur tire de chacun ce dont il a besoin et les fusionne.
Construire le modèle
Une fois la page fetchée, getInfo exécute trois passes. Chacune est enveloppée pour qu'un échec dans l'une devienne une erreur collectée sur le StreamInfo plutôt qu'une perte totale :
streamInfo = extractImportantData(extractor); // id, url, name, type, duration, age limit
extractStreams(streamInfo, extractor); // audio / video / video-only / subtitles
extractOptionalData(streamInfo, extractor); // description, thumbnails, uploader, relatedextractImportantDataconstruit leStreamInfoet est la seule passe qui doit réussir. Le chemin YouTube ici distingue aussi le contenu soumis à une limite d'âge de celui bloqué par pays, et lèveContentNotAvailableExceptionavec le vrai message du serveur au lieu d'un message trompeur.extractStreamstire les formats lisibles. C'est ce que le player consomme au final, et là où laDeliveryMethod(progressive, DASH, HLS, SABR) est décidée. C'est le sujet de Flux et delivery.extractOptionalDataest en best-effort. Une description ou une miniature manquante dégrade un champ, elle ne fait pas échouer la vidéo.
Le même squelette partout
Les listes suivent la forme identique, avec une étape en plus. Au lieu d'un seul getInfo, un ListExtractor renvoie getInitialPage(), et on parcourt getPage(nextPage) tant que hasNextPage() est vrai. Le fetch, les champs mis en cache et la collecte tolérante aux erreurs sont tous les mêmes. Remplacez StreamExtractor par ChannelExtractor ou SearchExtractor et les seules choses qui changent vraiment sont onFetchPage et la façon dont les champs sont parsés.