
El modelo InfoItem
La extracción produce dos formas de datos: un Info completo para la única cosa que abriste, y una lista de tarjetas InfoItem para todo lo demás. Ambas se construyen de la misma manera tolerante a errores.
Info: el objeto pesado
Info es la base de los objetos detallados (StreamInfo, ChannelInfo, PlaylistInfo, CommentsInfo). Lleva la identidad y una lista de errores tolerados:
int getServiceId(); String getId(); String getUrl(); String getOriginalUrl(); String getName();
List<Throwable> getErrors(); void addError(Throwable t);Esa lista de errores es toda la razón por la que una página medio rota sigue devolviendo algo: cada paso de extracción opcional añade a ella en lugar de lanzar.
InfoItem: la tarjeta ligera
InfoItem es la base de las entradas de lista, deliberadamente fina, justo lo necesario para renderizar una fila:
enum InfoType { STREAM, PLAYLIST, CHANNEL, STAFF, COMMENT, BULLET_COMMENT }
InfoType getInfoType(); int getServiceId(); String getUrl(); String getName(); String getThumbnailUrl();Las subclases concretas añaden sus propios campos:
StreamInfoItem:streamType,duration,uploaderName,viewCount,textualUploadDate+DateWrapper,uploaderVerified,shortFormContent, ...ChannelInfoItem:description,subscriberCount,streamCount,verified.PlaylistInfoItem:uploaderName,streamCount,playlistType.CommentsInfoItem:commentText,likeCount,pinned,replyCount, y unaPagede respuestas (ver Comentarios).
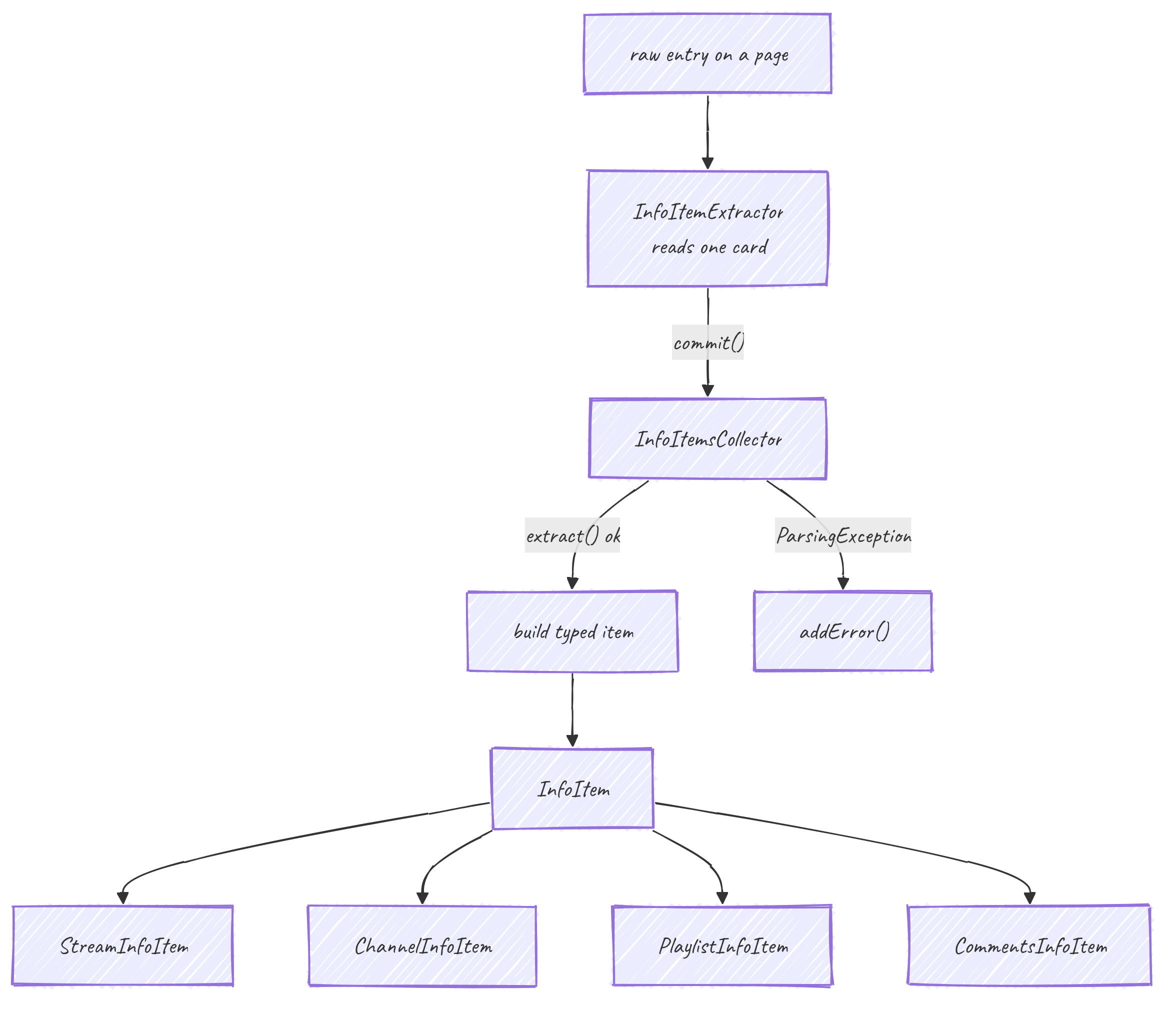
InfoItemExtractor: una tarjeta, de forma perezosa
Nunca construyes un InfoItem a partir de JSON en bruto a mano. Escribes un InfoItemExtractor, un objeto diminuto que lee los campos de una tarjeta bajo demanda:
interface InfoItemExtractor { String getName(); String getUrl(); String getThumbnailUrl(); }con subinterfaces tipadas (StreamInfoItemExtractor, ChannelInfoItemExtractor, ...) que añaden getDuration, getViewCount, etc. La mayoría de esos métodos son default y devuelven un valor vacío seguro, así que un servicio solo sobrescribe lo que realmente tiene.
Colectores: extractor dentro, elemento fuera
Un colector convierte extractores en elementos, de forma tolerante:
collector.commit(extractor); // extract(): addItem() on success, addError() on ParsingException / FoundAdException
List<I> getItems(); List<Throwable> getErrors();Hay uno por tipo (StreamInfoItemsCollector, ChannelInfoItemsCollector, PlaylistInfoItemsCollector, CommentsInfoItemsCollector). extract() es donde el elemento tipado se ensambla campo a campo, cada campo opcional envuelto para que un valor que falte no pierda toda la fila.
MultiInfoItemsCollector maneja listas mixtas (una búsqueda devuelve flujos, channels y playlists juntos): mantiene un colector por tipo y encamina cada extractor al correcto según su interfaz. Un colector también puede llevar un Comparator para mantener los elementos ordenados, y soporta el bloqueo de contenido (applyBlocking) para descartar elementos por palabra clave, channel, shorts o flag de pago.
Imágenes
Las miniaturas y los avatares están pasando de simples cadenas de URL a un Image más rico:
class Image { String getUrl(); int getHeight(); int getWidth(); ResolutionLevel getEstimatedResolutionLevel(); }
enum ResolutionLevel { HIGH, MEDIUM, LOW, UNKNOWN } // bucketed by pixel heightImageSuffix es la variante de plantilla (un sufijo de ruta más un tamaño objetivo) para los servicios que exponen una imagen base en varias resoluciones. InfoItem todavía conserva un getThumbnailUrl() para el camino simple.
StreamType
Cada flujo y cada elemento de flujo está etiquetado con un StreamType:
VIDEO_STREAM, AUDIO_STREAM, LIVE_STREAM, AUDIO_LIVE_STREAM,
POST_LIVE_STREAM, POST_LIVE_AUDIO_STREAM, NONEEl reproductor se ramifica según él (live vs VOD, solo audio vs vídeo), y la app también cuando decide qué controles mostrar.