
Architecture
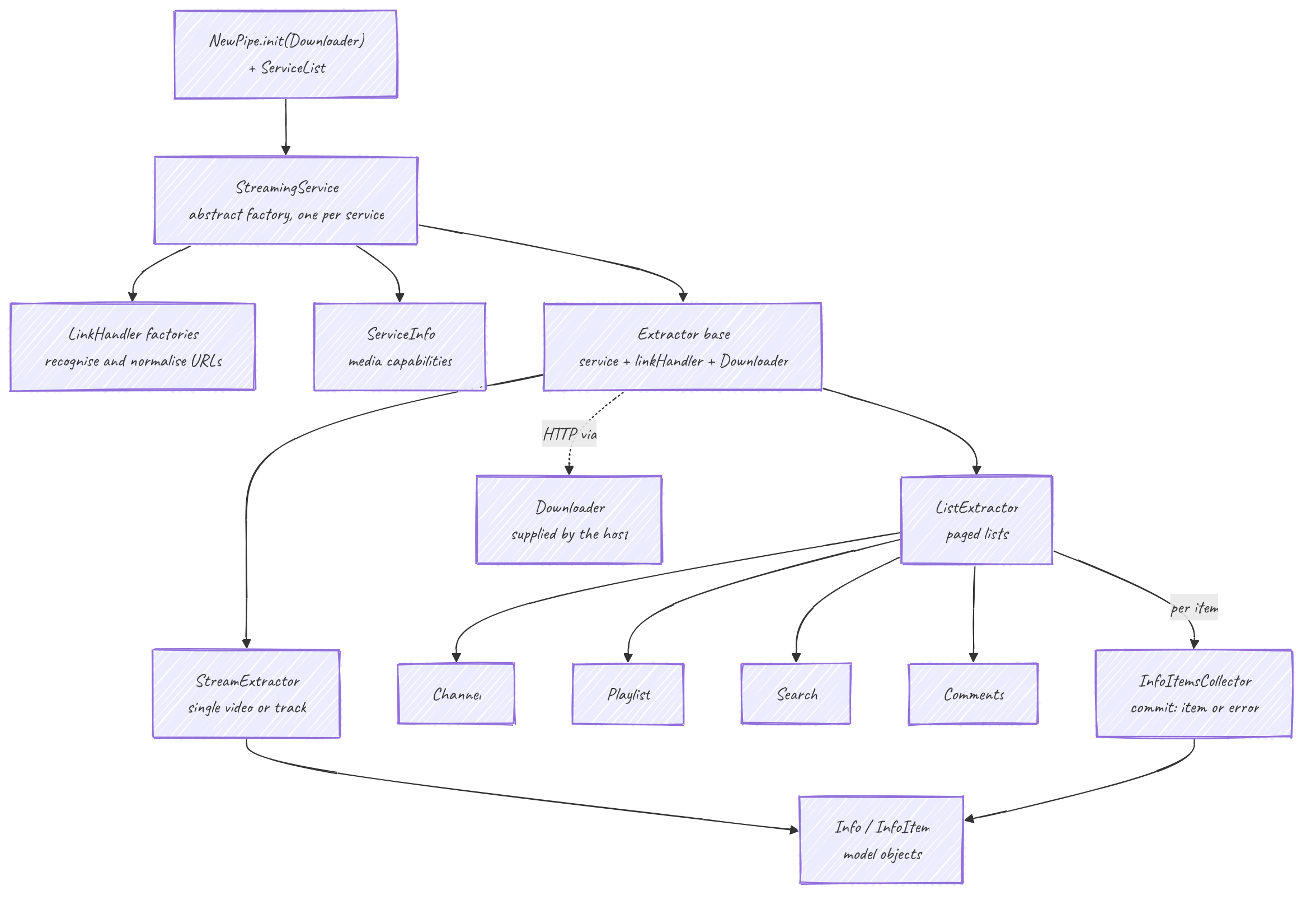
The extractor is built around one abstract factory per service. Everything else, URL handling, fetching, paging, model building, hangs off that factory in a fixed shape. Learn the shape once and every service reads the same way.
Bootstrap: NewPipe and ServiceList
Nothing works until the library is initialised. NewPipe.init(Downloader d) is called once at startup (overloads take a Localization and a ContentCountry). It stores the downloader and the default localization globally.
ServiceList is the registry: a fixed array of StreamingService instances, each created with a constant serviceId. That id is assigned here and nowhere else, so it stays stable across runs and can be persisted. Lookups go through NewPipe:
NewPipe.getService(int serviceId)
NewPipe.getService(String serviceName)
NewPipe.getServiceByUrl(String url) // asks each service if it accepts the URL
NewPipe.getServices()Every Extractor pulls the downloader from NewPipe.getDownloader() in its constructor, so init() has to run before you build anything.
StreamingService: the per-service factory
A service is an abstract class StreamingService, constructed with (int id, String name, List<MediaCapability>). The id comes from ServiceList, never from inside the implementation. Its ServiceInfo carries the capabilities the rest of the code checks before offering a feature:
enum MediaCapability { AUDIO, VIDEO, LIVE, COMMENTS, BULLET_COMMENTS, SPONSORBLOCK }The service hands out two families of objects.
LinkHandler factories, one per content type:
abstract LinkHandlerFactory getStreamLHFactory();
abstract ListLinkHandlerFactory getChannelLHFactory();
abstract ListLinkHandlerFactory getChannelTabLHFactory();
abstract ListLinkHandlerFactory getPlaylistLHFactory();
abstract SearchQueryHandlerFactory getSearchQHFactory();
abstract ListLinkHandlerFactory getCommentsLHFactory();Extractors, built from a handler:
abstract StreamExtractor getStreamExtractor(LinkHandler handler);
abstract ChannelExtractor getChannelExtractor(ListLinkHandler handler);
abstract PlaylistExtractor getPlaylistExtractor(ListLinkHandler handler);
abstract SearchExtractor getSearchExtractor(SearchQueryHandler handler);
abstract CommentsExtractor getCommentsExtractor(ListLinkHandler handler);
abstract SuggestionExtractor getSuggestionExtractor();
abstract SubscriptionExtractor getSubscriptionExtractor();
abstract KioskList getKioskList();There are convenience overloads that take a raw string and run it through the matching factory, so callers rarely build handlers by hand:
public StreamExtractor getStreamExtractor(String url) throws ExtractionException {
return getStreamExtractor(getStreamLHFactory().fromUrl(url));
}Finally, getLinkTypeByUrl(String url) returns a LinkType (NONE, STREAM, CHANNEL, PLAYLIST) by asking each LinkHandler factory whether it accepts the URL. That is how the app routes an arbitrary pasted link to the right kind of extractor.
LinkHandler: URLs in, stable ids out
A LinkHandler is an immutable triple: the original URL, a normalised canonical URL, and the extracted id. ListLinkHandler adds content filters and a sort order; SearchQueryHandler carries the query string.
The factory does the recognition:
abstract String getId(String url);
abstract String getUrl(String id);
abstract boolean onAcceptUrl(String url);
public LinkHandler fromUrl(String url) // acceptUrl() then build (canonical url + id)
public LinkHandler fromId(String id) // the other directionThe point is that recognition and normalisation happen before any network call. A messy share or mobile URL becomes a canonical URL plus a stable id that the rest of the pipeline can trust.
Extractor: the lifecycle base
Every concrete extractor extends Extractor. The base holds three things: the owning service, the linkHandler, and the downloader (resolved from NewPipe.getDownloader() at construction).
Identity is free, the rest costs a fetch:
getId(), getUrl(), getOriginalUrl(), getBaseUrl() // delegate to linkHandler, no network
getName() // abstract, needs the pagefetchPage() is the idempotent gate. It calls the abstract onFetchPage(Downloader) exactly once, guarded by a pageFetched flag, and concrete extractors do all their I/O in onFetchPage. Getters that need fetched data call assertPageFetched() first, so reading before a fetch throws an IllegalStateException instead of returning garbage.
ListExtractor: paging
Anything that returns a list, channel, playlist, search, comments, extends ListExtractor<R extends InfoItem>:
abstract InfoItemsPage<R> getInitialPage();
abstract InfoItemsPage<R> getPage(Page page); // a continuationInfoItemsPage bundles the items, the next Page token, and any per-item errors, with hasNextPage(). Sizes that cannot be known up front use sentinels: ITEM_COUNT_UNKNOWN, ITEM_COUNT_INFINITE, ITEM_COUNT_MORE_THAN_100.
StreamExtractor is the exception: a stream is a single item, so it extends Extractor directly, not ListExtractor.
Collectors: error-tolerant model building
A page does not build InfoItems by hand. For each raw entry it wraps a thin InfoItemExtractor (which reads one card's fields) and calls:
collector.commit(extractor); // runs extract(); addItem() on success, addError() on ParsingExceptionSo one broken card lands in getErrors() instead of sinking the whole page; getItems() returns everything that parsed. This is deliberate: services change their markup constantly, and a single unexpected entry should degrade one row, not the feed.
The output of all this is the Info / InfoItem model the app consumes.
That is the static map. To see these pieces run for one real request, from a pasted URL to a finished StreamInfo, continue to Extraction flow.