
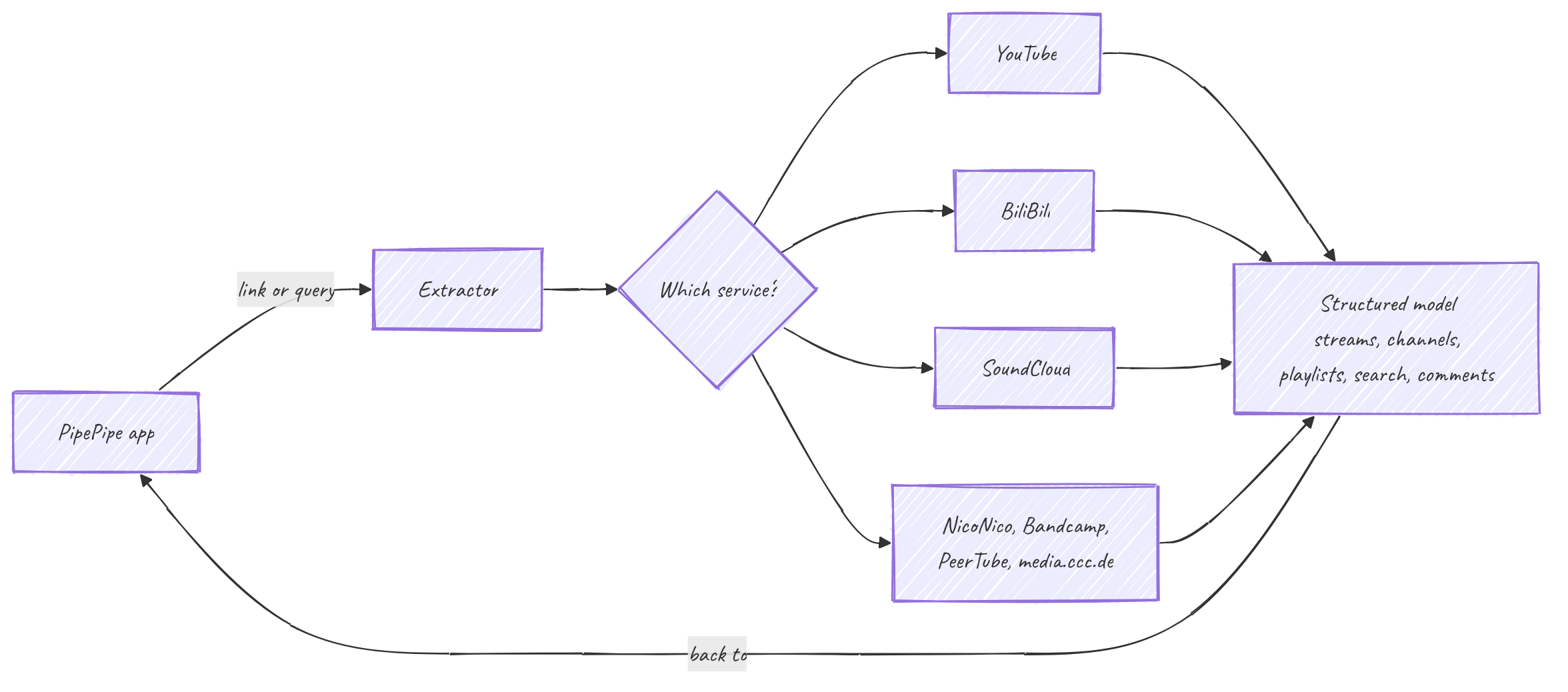
The Extractor
PipePipe never talks to YouTube, BiliBili or SoundCloud directly. Service access lives in the extractor, a standalone Java library the app depends on. You give it a link or a search query; it returns structured model objects: a video with its streams, a channel with its tabs, a playlist, a page of results, a comment thread. No HTML parsing or service API calls happen in the app.
It started as a fork of NewPipe's extractor, and the package path (org.schabi.newpipe.extractor) still shows it. That is worth stating once and then setting aside: the two codebases have diverged heavily. Services, abstractions, parsing, and behavior differ enough that NewPipe's documentation, issues, and patches rarely map cleanly onto PipePipe. Treat this as its own codebase, not a NewPipe mirror.
The module is self-contained. It builds and tests on its own, without the Android app around it, against a small Downloader abstraction the host supplies.
Services covered today: YouTube, BiliBili, NicoNico, SoundCloud, Bandcamp, PeerTube, and media.ccc.de. Each is a separate implementation of one shared set of interfaces. That is the design: the rest of the code is written against the abstractions, never against a specific site. "Get the streams of this video" is the same call whether the backend is YouTube or SoundCloud; the per-service mess stays behind the interface.
That uniformity is also why the extractor is the fragile layer. The interfaces are stable; the sites behind them are not. A service can change its layout or API overnight and break extraction for that one service while the others keep working. Most of the work here is keeping each service in step with a site that never agreed to be parsed, and YouTube is the loudest example.
What this section covers
A developer-level tour of how the extractor is built, for contributors reading the code.
- Architecture: the
StreamingServiceentry point and the family of extractors hanging off it. - Extraction flow: what happens from a URL to a finished
StreamInfo. - Streams and delivery: how media is described once extraction is done, the streams, formats, and
DeliveryMethods the player consumes. This is also where it connects to SABR.